Method
LDA topic modeling
A corpus-level language analysis pipeline — from raw term frequency and word distribution to latent topic discovery via LDA — built to inform the retrieval and content-understanding layer of the Learning Matrix.
Understanding what students actually ask — and how those questions cluster — is the foundation of a reliable educational AI. This analysis takes a technical Q&A corpus, strips it down to signal, and models the latent topic structure so the retrieval layer can retrieve, rank and explain answers with semantic awareness.
The pipeline runs in three stages: corpus statistics to understand term distribution, LDA topic modeling to discover latent themes, and interactive exploration to validate topic coherence before wiring the model into production retrieval.
Raw term frequency and vocabulary distribution — establishing which tokens carry signal and which should be filtered before modeling.
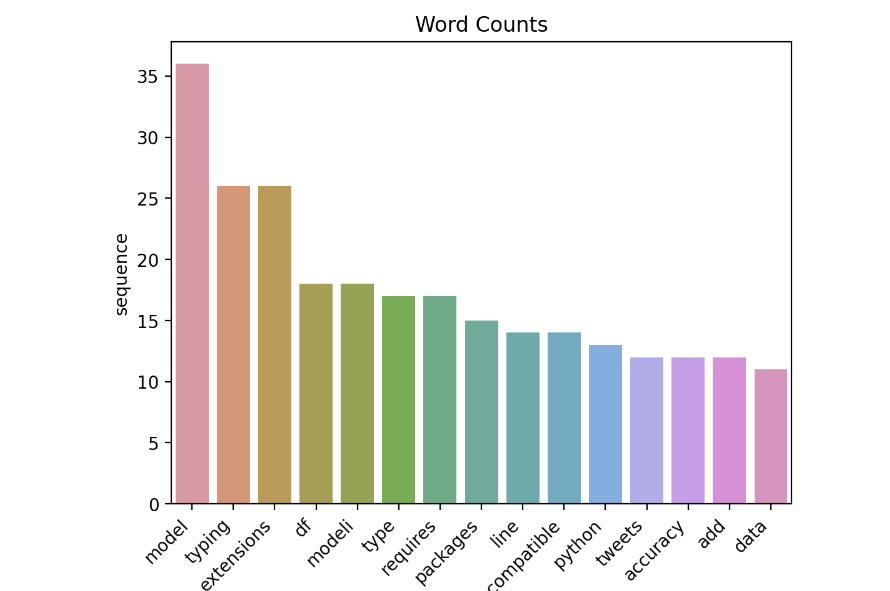
Fig 1. Word counts — top-15 most frequent terms. model, typing and extensions dominate; standard stopwords have been removed.
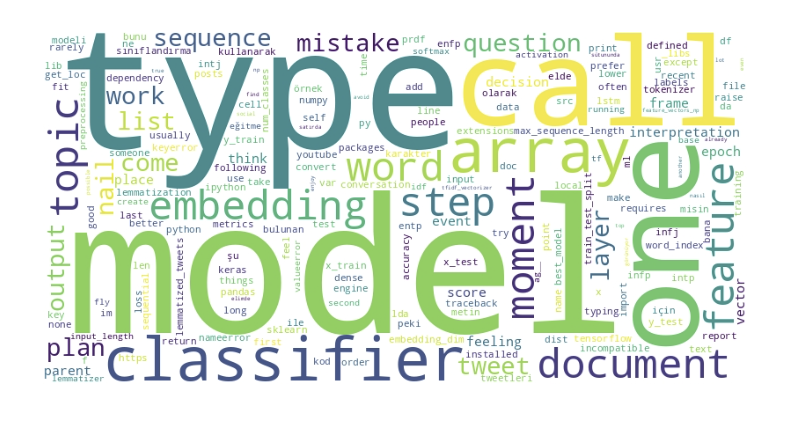
Fig 2. Word cloud — vocabulary weighted by term frequency. Dominant terms: model, classifier, type, one, sequence, embedding, document, feature.
Frequency: 36 — core concept threading every topic cluster.
Corpus is technically dense: embedding, classifier, sequence, feature co-occur at scale.
Stopwords removed, tokens lowercased and lemmatized before LDA input.
Latent Dirichlet Allocation over the cleaned corpus — discovering 20+ coherent topics and visualizing their separation and term saliency with pyLDAvis.
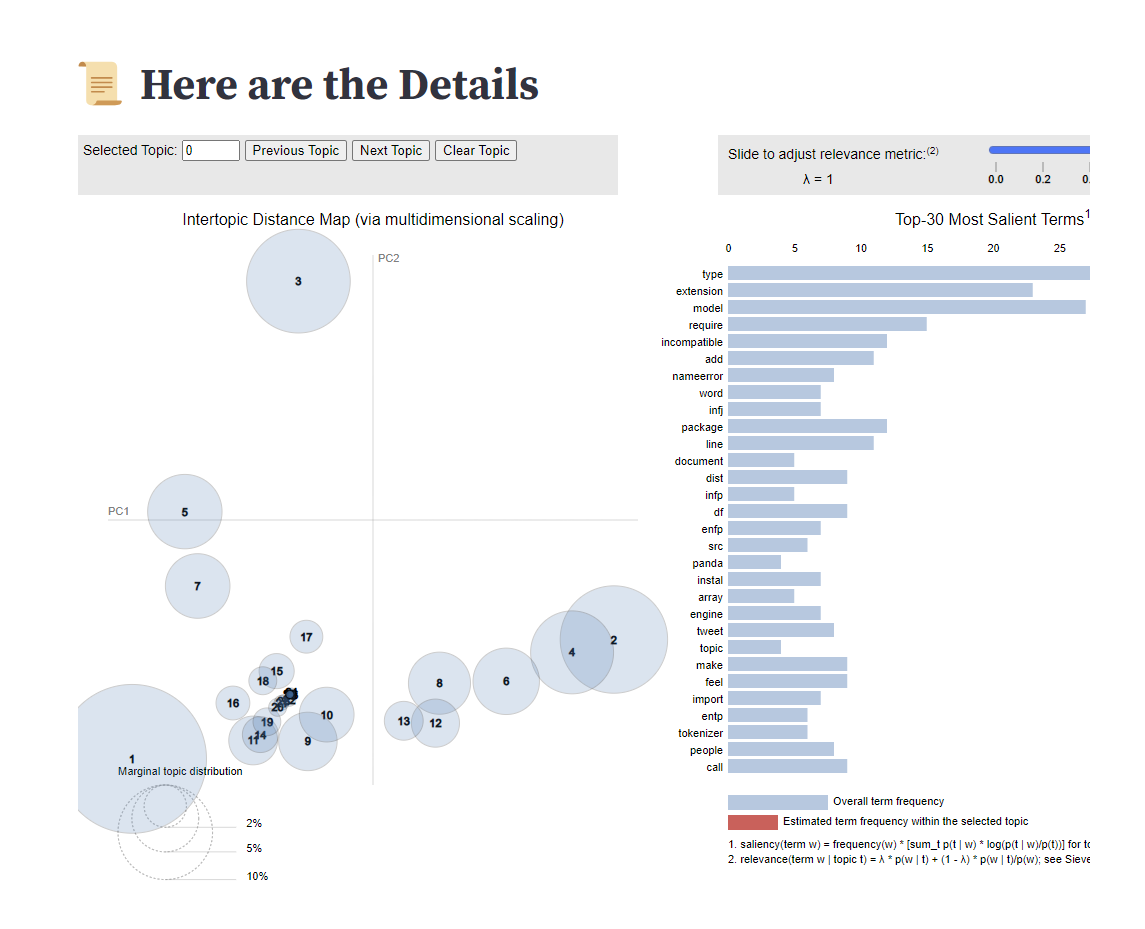
Fig 3. Intertopic Distance Map (multidimensional scaling onto PC1/PC2). Circle size = marginal topic probability. Topics 1–4 are large, well-separated clusters; Topics 5–20 are smaller, tightly packed niche themes. λ = 1 shows raw term frequency within each topic.
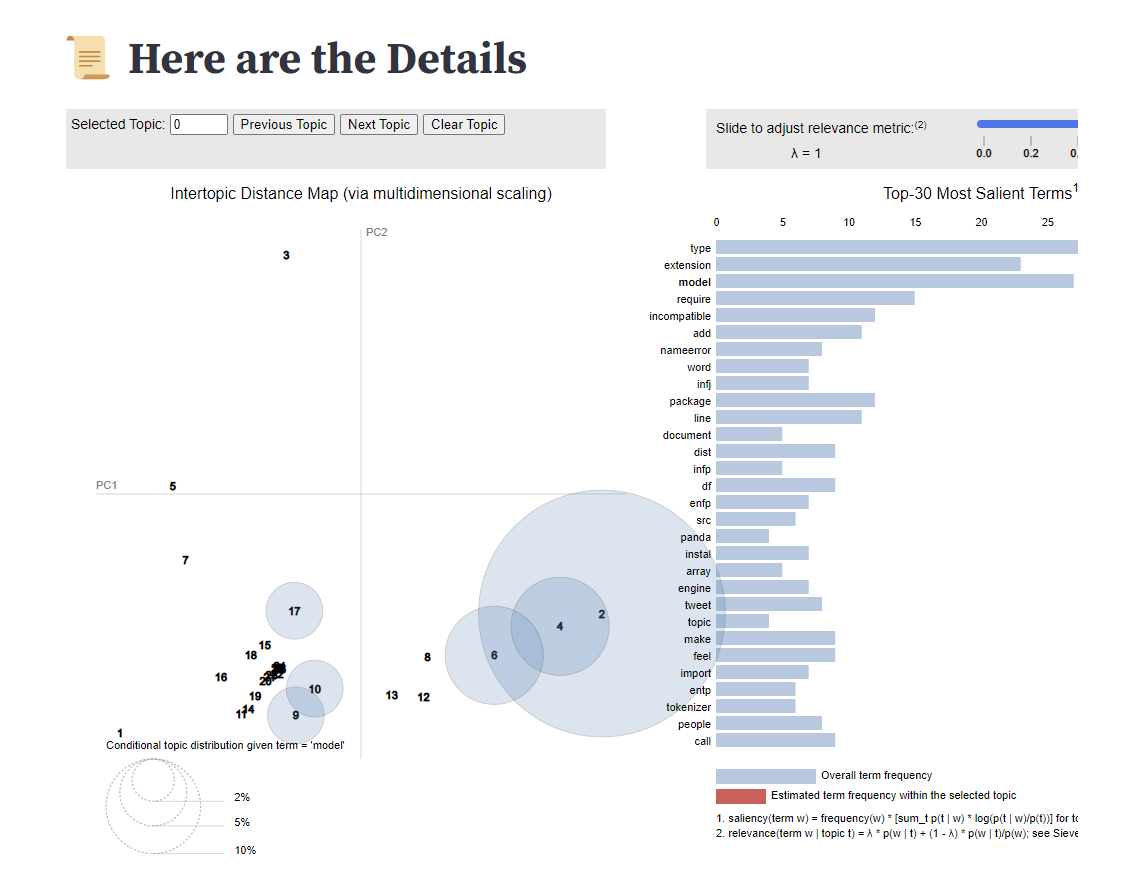
Fig 4. Conditional topic distribution given term = "model". The highlight shows which topics the term "model" loads onto — primarily Topics 2, 4 and 6, confirming model-centric discourse spans multiple distinct sub-themes.
Distinct latent themes extracted from the corpus.
Topics 1–4 are large and non-overlapping; tighter clusters in Topics 9–20.
λ = 0 surfaces topic-exclusive terms; λ = 1 weights overall frequency.